
The shift to object-centric process mining is enabled by a change in the underlying data model: from cases (which flattens source data to group events by a single primary identifier) to object-centric event data (which models relations between objects and events using many-to-many relations).
This shift also comes with a storage and performance overhead – making object-centric event data larger and slower to build and to query, being one of the hurdles for adoption of object-centric process mining.
Insufficient performance has often used as argument against using graph databases such as Neo4j for storing and querying object-centric event data. A typical question I would receive 5 years ago is:
“Nice idea, but can you handle 100 million events?”
In the past, I would answer:
“Not yet, but I will and all I have to do is wait and let the database community do what they do best: improve performance over data.”
Having now waited for about 5 years, where are we? And now I can answer:
“We are getting closer. The database community delivered faster systems and it’s time for us to start working with them – the systems and the community.”
In this post, I want to show what has happened regarding performance for object-centric and multi-dimensional analysis use cases.
A quick reminder on object-centric event data.
Object-centric event data is built on the following four concepts
- Events
- Objects (or more generally: Entities) – representing objects as well as any other, well…, entities, of interest to track over time which can be actors, machines, as interestingly also activities
- Event-to-Object relations (or correlation relations) expressing many-to-many relations between events and objects
- Object-to-Object relations describing which objects (or entities) are related to each other
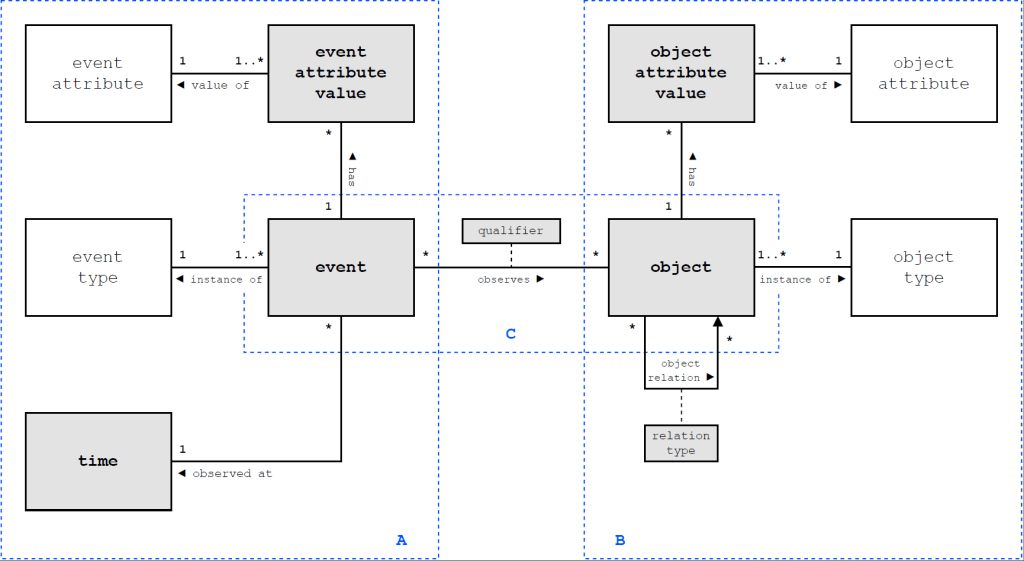
Next to this, process mining analysis infers and operates on behavioral relations between events, specifically the directly-follows relation per object (as explained in this blog post and these tutorials)
Various implementations of object-centric event data models exist, both over relational databases and over graph databases, see this report.
The hurdle for data systems to handle object-centric event data
One of the reasons that object-centric event data is more challenging to model and query is that it is conceptually more graph-based than relational and the existing standard data systems, relational databases and graph-databases, offer different trade-offs:
- Relational data systems are much more scalable, but the relational query-language SQL is not a good fit with the graph-based concepts behind object-centric event data
- Graph-based data systems more naturally allow to model and query the graph-based nature of the data, but – as they are relatively new – have not reached the performance levels of relational databases yet.
A recently published paper on Object-Centric Process Querying by Aaron Küsters and Wil van der Aalst paints the picture clearly. That task is to search for a subset of data (objects) that match a query pattern. For the moderately sized BPI Challenge 2017 event log (1.3 million events), these query patterns look for one or two related objects with two related events and some constraints over these events (involving approximately 3-4 joins in terms of a relational database).
For example, the following pattern (written in the query language Cypher) looks for all Applications where there is no related Offer that was accepted after the application was accepted.
MATCH (o1:Entity { EntityType: "Application" }) <-[:CORR]- (e1:Event {activity:"A_Accepted"})
WHERE NOT EXISTS {
MATCH (o1) <-[:REL]- (:Entity {EntityType: "Offer"}) <-[:CORR]- (e2:Event {activity:"O_Accepted"}) WHERE e1.timestamp <= e2.timestamp
}
RETURN COUNT(o1) as violationCountFor evaluating such queries,
- Neo4j takes ca. 1sec to answer the query – while the queries themselves are simple and very close to the pattern in mind, while
- Relational databases take 500ms to 100ms (fast in-memory) – while the queries are much longer and have not resemblance to the pattern in mind.

That paper shows also that the trade-off can be overcome by building a (dedicated) data model and nice (visual) query interface that allows to answer these queries within 50ms. In other words, the trade-off stated between relational and graph-based systems is not inherent, but we can build modeling and querying object-centric event data can be done, both, highly scalable and with simple, easy-to-understand queries.
But it requires engineering homework.
Who should do the engineering?
This raises the question who should do the engineering?
In the following, I will show that the database community is already doing the engineering to deliver faster performing systems. But I will also show that – to really reach desired performance levels – we need to educate the database community about our use cases.
Using standards gives faster performance with zero effort: switching to a different DB
Let’s zoom out. Over the last years, we developed Event Knowledge Graphs (EKGs) as versatile data structure for object-centric and multi-dimensional event data. Since its inception, EKG’s provide the core concepts of object-centric event data and allow to materialize further analysis information – such as the directly-follows relations – for faster performance.
Event knowledge graphs are based on labeled property graphs – a data model that is supported by a range of graph database systems.
Over the last years we have used the graph database system Neo4j to develop and demonstrate the concept of EKGs for object-centric and multi-dimensional event data analysis. Neo4j is helpful as it is robust, has a very extensive implementation of the graph query language Cypher and has a fairly versatile visual and interactive query interface. This allowed us to iteratively try out and improve ideas before turning them into modules of the Python library PromG for ETL, data modeling and process mining using graphs.
But – as the experimental results on OCPQ above show – Neo4j is not the fastest data system for object-centric process mining.
However, our development approach for EKGs and their usage has been to build all data modeling and querying on open standards – the labeled property graph model and the query language Cypher (which is slowly being transformed and absorbed into a new graph query language standard).
Using open standards allows us to move ETL pipelines and analysis queries for EKGs from Neo4j to a different graph database. One such alternative is kuzu db – a very light-weight in-memory graph database.
Building and Querying Event Knowledge Graphs with kuzu db
Triggered by the above OCPQ experiments I adapted the ETL pipelines to build EKGs from CSV files we wrote for Neo4j to work for kuzu db. The biggest challenge (and also reason for performance gains) was that
- Where Neo4j uses an open schema, i.e., any node can have any attributes and any relation can be modeled between any two nodes,
- kuzu db uses a strictly typed schema for nodes and relations requiring to pre-determine the node properties and the source and target nodes of relations
While this requires some additional effort in making the data model during ETL more explicit, the actual ETL queries could be effectively reused (with one exception I will reflect on later in the post). The queries to build an EKG for BPI Challenge 2017 for kuzu db are available on this github repository: https://github.com/multi-dimensional-process-mining/graphdb-eventlogs
Doing this, we already see a performance improvement just for building the EKG.
- Where Neo4j needs about 8 minutes for BPIC 2017 (and approx 20 GB of RAM),
- kuzu db succeeds in just under 2 minutes 30 seconds (and approx 3-4 GB of RAM) – of which 1min 14secs are spent on materializing the directly-follows relations
Running the OCPQ queries on the event knowledge graph in kuzu db, we immediately get a performance improvement of factor 5x to factor 10x (as shown in the table below under KuzuDB – Generic Schema), from 723-1530ms for Neo4j to 57-261ms for kuzu db.
The development effort for this performance improvement for me was about 5-6 hours in total – and most of it was spent in looking up the kuzu db documentation. I would consider this a perfect division of work for lowering one of the hurdles for adopting object-centric process mining.

Gaining more performance with (some) effort
During this small engineering exercise, I stumbled over two things that significantly helped increase performance – but where I had to work “around” the capabilities of the current data systems to achieve desired or improved performance.
Both are concerned with building object-centric event data models but have a different focus:
- faster operations for inference in OCED, and
- different physical data modeling for faster querying
Native PM operators in DB systems
When building the EKG for BPI Challenge 2017, I also tried to materialize the directly-follows relation using the standard query we are using with Neo4j
MATCH (n:Entity)
MATCH (n)<-[:CORR]-(e)
WITH n, e AS nodes ORDER BY e.timestamp, ID(e)
WITH n, collect(nodes) AS event_node_list
UNWIND range(0, size(event_node_list)-2) AS i
WITH n, event_node_list[i] AS e1, event_node_list[i+1] AS e2
MERGE (e1)-[df:DF {EntityType:n.EntityType, ID:n.ID}]->(e2)It retrieves all events related to an object, collects these events (ordered by time) into a list and then iterates over the list to materialize a directly-follows edges between two subsequent events. Not very elegant in terms of graph queries, but it gets the job done and shows how process mining sees graphs somewhat differently than other domains.
Kuzu db cannot execute this query in a performant way – it simply runs out of memory within 30 seconds as it lacks a batching mechanism to break up the query workload into smaller parts (e.g. per object) that requires much less memory. In contrast, Neo4j provides such a batching mechanism.
So, to build the directly-follows relation, I had to realize a different “around” kuzu db to build the directly-follows relation in a faster way, which consists of
- Querying a table (view) of event identifiers and object identifiers, sorted by object id and by event timestamp – now the table is built of “blocks” of events related to the same object)
- Translating this table into a Python dataframe,
- Appending a copy of the object id + event id columns to the dataframe (as “target object” and “target event”) and shifting the “target object” and “target event” columns up by 1 – now each row holds and object id + event id and the target object id and target event id of the “next” event
- Removing all rows where object id and target object id are different results in the pairs of events connected by directly-follows
- We then can bulk import this table into the graph database as directly-follows edges
This process mining-“native” operation is much faster and scalable than the query above, but ideally wouldn’t require moving the data out of the database and back in. Rather, it should be an operator in the database. But the database community will only know this if they hear from us that this is an important use case.
Flexible vs performant data modeling
Another performance gain comes from a different physical data model. It’s a lesson well known from relational databases, but not exploited much for graph databases.
When transferring the ETL for building and EKG to kuzu db I used the generic OCED data model concepts, specifically all objects are represented as generic :Entity nodes and their specific type is expressed through a property of the node.
We already have seen in prior studies that practical applications benefit from explicitly modeling the domain’s concepts, i.e., using :Application and :Offer nodes to model application and offer objects.
I also explored this way of modeling in the ETL for kuzu db. Physically, kuzu db creates one table per object type (with its own index). Also relations get typed in this way as a relation table now links from one typed table to another typed table.
Technically, this applies vertical partitioning of a generic table into multiple tables of a specific type. Adapting the queries to explicitly refer to the typed relations yields another performance boost (in the table above listed under Kuzu DB – Typed Schema):
- kuzu db now can answer queries faster than Duck DB and sometimes even faster than the bespoke and optimized OCPQ implementation
Achieving this results took me
- about 2 hours to update the ETL has I now had to build more complicated Data Definition Language (DDL) statements for a fully typed schema (though the principles should generalize easily), and
- about 1 hour to rewrite the queries to the fully typed schema (though again, with a good data model in place, queries over a generic model should be easily translatable to a typed model as all replacements were local)
The entire ETL and OCPQ experiment on kuzu db is available here: https://github.com/multi-dimensional-process-mining/graphdb-eventlogs/tree/master/csv_to_eventgraph_kuzudb
The beauty of achieving this performance with kuzu db is that it required comparatively little effort for the performance gains achieved, while still building on a general purpose data system with a generic query language allowing to be extended with other operations and other types of queries for object-centric process mining.
So, we now just wait?
Overall, I think that the strategy of letting the database community do what it does best – deliver high-performance data systems – is already paying off for process mining. As illustrated for Event Knowledge Graphs:
- We can gain already state-of-the-art performance and scalability using off-the-shelf data management systems with very minimal effort.
- The remaining “minimal effort” is nevertheless non-trivial as it touches at the very interface between data management systems and process mining and requires a very good understanding of both.
That also means the time for “just waiting for the other side” is over – it is time to engage with the database community at a deeper, conceptual and technical level to help them build the data systems that support object-centric process mining use cases at scale.
What exactly we need, we are still figuring out. I believe we need the capability to build various forms of process mining specific abstractions and analysis results – to be directly materialized next to the data itself, such as
- inferring new object relations and their temporal order
- object variants (transferring trace variants to an object-centric setting)
- object-centric start-to-end executions (generalizing the classical case concept to an object-centric setting)
