
This post summarizes my talk on “Data Storage vs Data Semantics for Object-Centric Event Data” I gave at the XES symposium at the ICPM 2022 conference.
I first provide a bit of background and the problem we faced, before I turn to the issue of separating data storage from data semantics.
Background
Process Mining analysis starts when someone made event data available in a form that can be directly loaded into a process mining solution. Providing data suitable for analysis is a very labor-intensive process in itself, often taking the lion share of time until the first insights are obtained. Event data exchange formats are supposed to lower the hurdle by providing a common set of semantics concepts that all process analysis problem share.
The existing XES standard suffers from the limitation of pre-grouping events under a single case identifier, which makes it hard to use for analysis questions on many real-life systems. Aware of this problem, the process mining community has started a working group to develop a more versatile event log standard, currently called Object-Centric Event Data (OCED). A first intermediate result of this discussion is a meta-model that illustrates which key concepts we need to consider in data exchange.

The OCED meta-model tries to strike a careful balance between having a simple standard and adding more expressivity to event data exchange formats that includes:
- Not pre-grouping events under a single case identifier.
- Making events and data both first-class citizens in the data to properly express how a process operated over rich data structures including.
- Expressing operations at least over the basic entity-relation model (object, relations, attributes) to address a broad range of use cases.
- Not include all semantic features that are important to a number of specific use cases, but not generic enough to force all other use cases to also deal with them.
- Be easy to adapt and use by industry to provide data in this form.
- To be expressive enough to support the fundamental concepts of object-centric process mining or multi-dimensional process mining over multiple entities.
The problem: expressing semantics in data storage make things complicated
Increasing the expressiveness of the data exchange format with concepts to describe how events operated over an entity-relational data model has an undesired consequence: the meta-model to describe all possible ways of how data can be operated on has to suddenly incorporate a large amount of semantic concepts. At the bare minimum, this is creating, reading, updating, deleting objects, attributes, and relations individually and together. At the same time, using just the bare minimum of concepts immediately reveals use cases that cannot be naturally expressed, asking for even more semantic concepts.
How to escape this dilemma was the topic of my talk, which I developed over many discussion with Marco Montali.
Separating Data Storage and Data Semantics
The fundamental point I am making is that the meta-model for data exchange in process mining has to separate the data storage from the data semantics.
Which problem are we solving with data exchange?

We want to help an analyst solve an analysis task for a real process. The analysis fundamentally is to understand the “ground truth” of the dynamics in the real world and to map it to an analysis artifact (digital image, shadow, twin, …) that is consistent with reality for the specific analysis task. A major complication in understanding processes operating on data is that these operations come at different levels of granularity:
- Basic atomic data operations,
- grouped into database transactions,
- organized into process-level actions or activities
- that are structured by the process.
Because inspecting reality is costly, we pass the data recorded by the underlying IT systems to process mining analysis tools which can reconstruct this digital image of reality. Again, that image has to be consistent with the ground truth of the real process to be of value.

The data exchange format has to allow this – no more, but also no less.
The problem of data provisioning
Unfortunately, the data storage in the underlying systems is optimized for usage: entities and objects are distributed over multiple tables, there are no events, just time-stamped records, relations can be expressed in many ways, activities are materialized in various forms. Moreover, data recording is “lossy” from the perspective of a historic analysis: certain data is never recorded or recorded incorrectly, other data is discarded when it’s no longer needed for operations.

As a consequence, the recorded data may (in parts) be inconsistent with the ground truth:
- Objects and events may be stored at higher or lower level of granularity that experienced in reality.
- The scope and semantics of operations on data is vague or ambiguous: which objects, relations, and attributes were involved in a change of data at which point in time?
While these inconsistencies are ideally resolved by improving the data storage of the underlying IT systems, in reality most systems will store inconsistent data. As “consistency with the ground truth” is depending on the analysis task, it is impossible to fully resolve it when exporting the data into the data exchange format.
I therefore argue that the data exchange format should facilitate fast data exchange and rather write out data as-is (as it’s issues and problems are also known). A fundamental property of this data export must be
- Data that already is consistent with the ground truth also stays consistent with the ground truth.
- Data that is inconsistent with the ground truth is allowed to stay inconsistent – resolving in consistency requires more information that is better addressed in the analysis phase. But obvious inconsistencies should be resolved through simple data transformations as early as possible.
This doesn’t tell us yet how the exported data should be structured. For this, we should look at what we need to do with the data.
Necessary separation of data semantics for process analysis
Even the most basic, classical process mining analysis already separates data semantics from data storage. Classical process mining starts from building a classical event log. The de-facto standard are CSV files where one column holds a timestamp and other columns essentially hold a number of attribute-value pairs. To turn this CSV file into an event log, the analyst has to pick one attribute that as case identifier and another attribute as activity.

And the analyst has to make this choice in line with the analysis task and what makes the data (more) consistent with the ground truth. This may require to combine multiple attributes to define the right case identifier to refine activities by using multiple attributes.
The space of choices simply becomes larger when we start including dynamics over data in the question.

We now have to make choices for how to model the dynamics of various entities (data objects, actors, equipment, …), relations, and attributes over various levels of granularity (from basic data operations via transactions to actions and entire processes). Each real-world process has its own, specific data structures. The analysis fundamentally has to reconstruct relevant aspects of these data structures (consistency with domain knowledge) in line with the analysis task. This requires flexibility during the import – specifically because different analyses may focus on different aspects.
This suggests that we should generalize the choice of activity and case identifier we do in the classical case to a description of how the recorded and provisioned data maps to the domain knowledge. This would provide the analyst with the design space to build their analysis.
Proposal: A Semantic Header for Event Data
We can create a separate semantic header that is separate from the raw exported data exported. This header has to how the stored data maps to the domain data model of the process.

The storage format for the raw exported data has at least to be:
- a collection of time-stamped records, where
- each record holds information about a relevant change to the process and its data – stored in a number of attribute-value pairs.
- The values can be rich data structures themselves – directly retrieved from the source system.
On top of this, a domain export provides a semantic header that consists of
- The domain data model over which the process operates
- A mapping how the attributes and values stored in the data relate to the domain concepts.
This semantic header is not tied to the specific data export. It can be provided beforehand, but also be revised and updated after data export as the analysis evolves or better domain information becomes available. This allows to gain more insights on previously exported data without having to re-export the data again.
To enable process mining over multiple objects, the semantic header has to to express at least which attributes and values describe objects, identifiers, the relevant relations between them – and which attributes belong to an object (are stored somewhere) and which attributes belong to an event (are just observations of a context that is not further stored). This is essentially what the OCED meta-model tries to achieve.
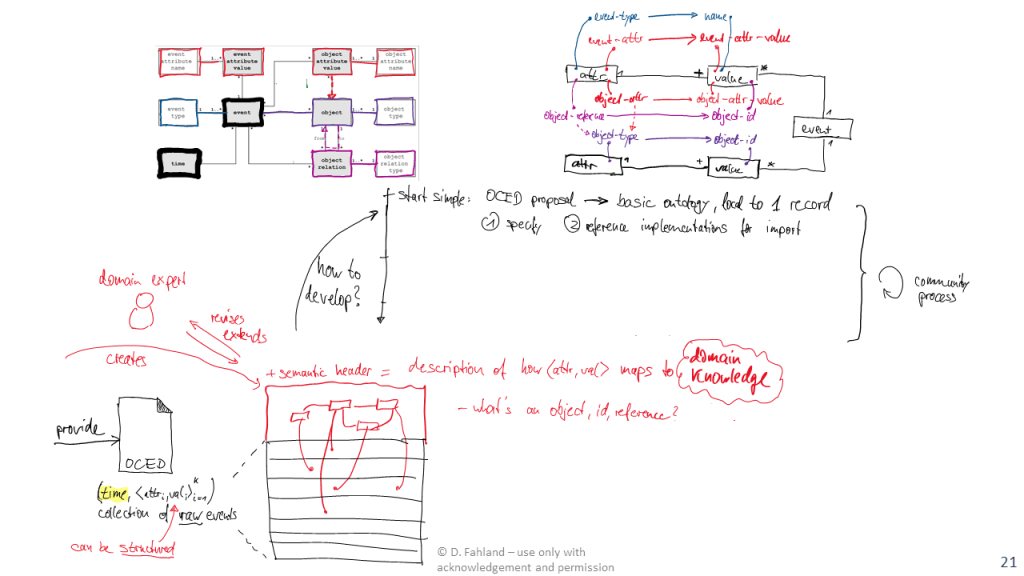
How could demonstrate the feasibility of this semantic header for solving this data exchange problem? The top-part of the above figure sketches how we could specify a mapping from attribute-value pairs of a raw data export to the basic concepts of the OCED meta-model:
- Some elements of the process data model can grounded in a single attribute, e.g., which attribute holds an object identifier, or which attribute holds an event property.
- Some elements of the process data model need grounding in multiple attributes, e.g., we need the attribute which holds the identifier id of an object type O and the attribute which holds the value a property x of objects of type O.
This mapping only grounds the objects in the recorded data. We still need to map out the semantics of the operation on the data, which is represented in the OCED model as qualifiers of the relations between events and objects, attributes, and relations. This could for example be done by rules over the attributes such as: If event has type “Create Order” and refers to an object of type Order, then this object is created by the event.

While these semantic concepts can be grounded in a single event record, other concepts may need grounding in multiple event records, such as: which events together from a batch, which events belong to the same activity (start and end events), or which events modify a relation that was created previously.
Some of these process dynamics will be common among many processes, and also be stored using very similar or identical data structures. Others will differ strongly among processes and be represent very differently. By developing the key concepts for specifying semantic headers of process event data, we give an analyst the flexibility to specify the exact semantic model required for the specific process and analysis – without polluting the data storage format with the specifics of the process.
As a community, we have the obligation to help standardize semantic concepts of process that are shared by many processes. The OCED model is arguably the shared baseline. We should start here and create a few proof-of-concept implementations of semantic headers and functions for OCED that transform basic CSV (or OCEL) files into data analysis structures, specifically for object-centric process mining and event knowledge graphs.
