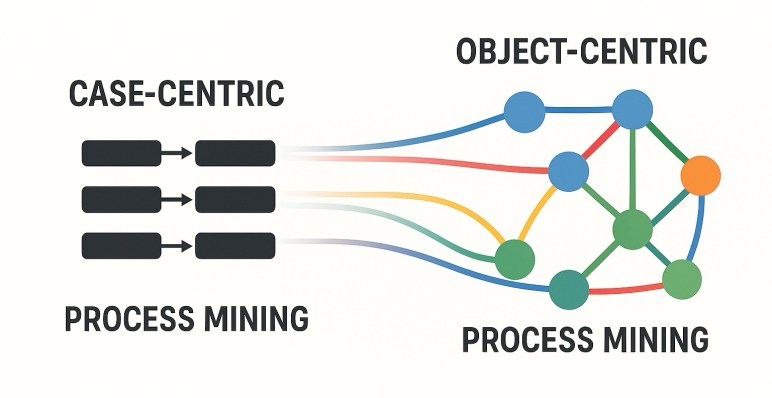
Over the last months I had various exchanges with practitioners and vendors in process mining on the topic of Object-Centric Process Mining (OCPM). And while the idea has been around for a while, industrial adoption remains a challenge even for seasoned experts. But why is that?
From these conversations I gathered that adopting OCPM faces different hurdles than getting started with process mining in general.
In the following, I want to summarize and reflect on my insights from these conversations. And I hope they help the PM community – researchers, vendors, and practitioners together – to ease the transition to OCPM.
OCPM
The idea of Object-Centric Process Mining (OCPM) is directly analyze the events in relation to the objects and relations we see in the data (as a network of events and objects) instead of extracting cases (as sequences of events) which distorts and transforms the data. In essence, with OCPM, analysts
- no longer have to duplicate events when extracting cases and no longer miss events – leading to correct statistics,
- no longer introduce false ordering of events (on different objects) – leading to correct performance and flow analyses, and therefore
- can model, view, and analyze the data closer to how “the process actually is”.
How mature is it?
The term OCPM itself has been coined in 2019 with first roots in 2017 and in 2018. Yet, the topic of modeling and analyzing processes “as-is” rather than through artificial sequences of events is almost as old as the field of process mining itself. Much development happened under the term “artifact-centric process mining” from 2010 onwards with first data models and algorithms for “events related to multiple different objects” implemented in ProM already in 2011 until 2013 in various approaches and validated in industry.
These ideas eventually evolved into OCPM by 2019.
Having researched artifact-centric and object-centric process mining myself for 15 years, the first and biggest hurdle has been to get the key idea and concepts right and simple. As simple as possible. This took multiple (slow) iterations and independent contributions – but I think we are now there. This keynote talk explains how this happened and what the simple core of OCPM is.
And as true testament to the simplicity achieved and the innovative power of the process mining industry, we saw the first commercial OCPM implementations (sometimes under different terms) already in 2021 and 2022:
- by Mehrwerk Process Mining (now mpmX): MPM OCPM demo video (I saw demo during the ICPM 2021 in Eindhoven)
- by Celonis where the topic got center stage and wide attention at Celosphere 2022: Celonis OCPM demo video
- by Konekti when presenting their reference implementation of an object-centric event data model for data extraction and transformation in 2023
- by ServiceNow (at latest in 2024): ServiceNow Washington DC release video
- Did I forget an industrial implementation? Let me know
The idea and principles of OCPM are now viable for industry adoption.
If it’s so good, why isn’t everyone doing OCPM?
Despite all these tangible benefits and demonstrated viability, OCPM has not become the mainstream approach to process mining. Many vendors and practitioners are adopting OCPM much more slowly. If it’s so good, why isn’t everyone doing OCPM?
The first hurdle has been take : OCPM had simple enough concepts to allow others to adopt it(see above). So, it can’t be the complexity of the ideas or theory behind it.
And indeed, the discussions I have been having with practitioners and vendors on working with OCPM all start from the point that they do understand the concept, benefits, and potentials of OCPM. So, it’s also not about lack of explanation or education about the concept – as there are online learning resources and courses available.
What I rather gathered from my exchanges is that process mining practice has accrued a socio-technical debt. Let me explain.
The socio-technical debt of “the case concept”
Getting started with OCPM is surprisingly expensive if you already have a successful practice or product for process mining in place. Even so on the processes that we always consider as the main motivator for OCPM: Order-to-Cash, Purchase-to-Pay, Accounts Receivable, etc… – processes that manage many objects in complex relations and where event log extraction falsifies statistics and process information.
Why is that? Because 20 years of efforts spent in dealing with these processes in a case-centric manner:
- If you are successful as practitioner or vendor in process mining, then it’s because you learned how to engineer and maneuver your way around the pitfalls of building a sufficiently reliable process mining analysis: you already managed to align data extraction and transformation into classical event logs with the analyses and KPIs that lead to actual insights.
- You found ways and strategies to deal with convergence and divergence when translating the rich, multi-dimensional structure of the source data into a flat log. By smart scoping in data extraction, by correcting extraction and calculation error in KPIs and in Dashboards, by combining careful data processing, best practices of analysis, and by training on how to interpret the data correctly and by cross-checking your results you ensure that you draw reliable conclusions.
- You do have a tech stack that can handle 100 million or 1 billion events.
The entire process mining pipeline and software stack from conceptualizing the process mining project and scoping the data to extraction, modeling, aggregation and querying and computation (generic and use-case specific), dashboarding and user-flow is a result of 20 years of well-developed conceptual and methodological thinking and countless person years of software engineering and training. As a software vendor and as a practitioner dealing with a sizable information systems and regular process mining activities, you have built up
- A non-trivial software stack fully tailored to case-centric process mining
- A non-trivial methods catalogue and organizational embedding that both relies on and caters to this software stack.
Object-centric process mining touches this complex socio-technical construct at its very foundation and
- throws away the one constant all process mining can rely on: “the world is a set of cases, each being a sequence of events with a clear start and end”, and
- replaces it with “the world is a network of objects and events and where it starts or ends is up to you and your curiousity”
- and it hasn’t seen 20 years of engineering – yet.
I am not saying that our 20 years of knowledge of doing process mining is now obsolete. To the contrary, everything we learned is valuable.
However, the way how our existing case-centric process mining solutions combine and integrate this knowledge is not working for OCPM and has to be revised. In software engineering this is called technical debt. But for process mining, it’s not just software but also the processes of using it for analyses and their integration in the organizations that use it. So it’s a socio-technical debt.
How do we handle our socio-technical debt of “case-centric thinking”? How do we migrate?
Reducing technical debt is hard – especially if it is in the very systems that you rely on to generate revenue or reduce costs. We cannot simply swap out a classical case-centric solution for an object-centric one. Instead, we need migration strategies.
This is something that we have not been discussing in the process mining community so far – at least not broadly and certainly not within the academic community.
So while we are at the topic, I want to throw out some ideas and thoughts – hoping that they resonate and lead to a dialogue and fruitful collaborations and (research) projects between researchers, practitioners, and vendors.
While the “usual suspects” of standard processes such as O2C, P2P, AP etc. are strong motivators for OCPM, they are – on my opinion – not the primary business case for developing OCPM capabilities (as vendor or practitioner). You already know how to handle them sufficiently well. There may not be sufficient return on the investment needed to build OCPM capabilities for these processes. At least as long as the only objective is to just do what existing PM solutions do but now “the right way”.
Instead, we have to focus on use cases that are prohibitively expensive to do in a case-centric setting, either because it requires far too much custom logic and one-off analyses or because it requires seasoned experts with 10 years of experience to handle. What are these use cases? What are their characteristics? What exactly is costly and how will an OCPM-based approach lower the costs?
But I’d go even further and look at use cases and domains that were outright impossible to be addressed in a case-centric setting simply because all relevant insights cannot be captured in event sequences at all. Prime examples are all processes dealing with physical materials (material handling, manufacturing, logistics) where the actual objects being moved and combined matter.
We have seen substantial success in building OCPM ETL and analysis stacks for industrial use cases from zero in a span of 6-9 months in such use cases, for example
- Understanding how shared resources impact and delay parallel manufacturing in shipyards
- Improving data quality for tracking items in semiconductor manufacturing
- Identifying performance bottlenecks and their root causes in Airport Baggage Handling systems and understanding how equipment behavior impacts process KPIs
- Analyzing configuration management of complex high tech systems to understand (and eventually predict) conflicting changes to product configurations
- Analyzing complex working patterns of workers in sterilization centers for medical equipment
- Data modeling for understanding the process and entity in auditing and Automated checking of controls for auditing

All these use case had in common that their application domain has
- a genuine interest in the objects themselves and how they are handled over time, and
- there was no existing (successful) process mining implementation in place that would constitute a technical debt in a technical or socio-technical sense. In other words: it was only necessary to discuss how to realize an object-centric approach and tech stack and not how to re-engineer an existing approach (higher costs) or abandon an existing approach (sunk costs).
By their very nature none of these use case could exploit or re-use existing process mining algorithms because we were addressing questions that no existing algorithm could answer on data that no existing algorithm could consume. Everything had to be re-implemented. And each implementation was a one-off exercise. That is not a scalable model for developing standard process mining platforms to be customized, but we can make it a scalable model for letting data and problem owners develop their use-case specific process mining solutions: they have full access and knowledge of data and problem while a lot of “low hanging fruits” in OCPM do not require sophisticated algorithm engineering but succeed with good data modeling and querying using standard data bases. This was not a viable pathway to implement process mining in the case-centric setting 20 years ago, but could be a viable pathway in an object-centric setting with the currently available technology.
Doing so and documenting these as case studies would specifically provide the community with a trove of new process mining use cases and challenges for Object-Centric Process Mining.
Moving away from the use cases and opportunities to technical challenges…
Building an OCPM stack and approach changes the importance and boundary between the process mining analysis and the underlying data management solution (and the associated competencies to build and use it).
Classical event logs are a challenge for relational data management – as a case comprises multiple records – but rather suitable for classical algorithms which are good in iterating over sequences and collections.
Object-centric event data is a challenge for both: while the objects and relations are naturally represented in relational data models, event sequences per event and their ordering across events is not naturally modeled in relational data. While graph data models can capture this more naturally, the technology is not mainstream yet and is not (yet) as scalable as relational solutions. At the same time, process mining analyses still require iteration. This means we benefit from “moving process mining closer to the data” but we cannot fully move it to the data as the data system technology is not ready for it yet. And there are analysis steps that are always better done in dedicated algorithms. So we have to revisit the best practices and optimizations for dividing data modeling and analysis between database and algorithms that we built over the last 20 years. This will take time and detailed, careful research.
When replacing a case (or event sequence) with a graph of objects and events, previous process mining algorithms no longer apply while entirely new algorithms are needed to deal with and analyze dynamics in an interconnected setting. But these can only be developed at scale when use cases are clear.
Moving to OCPM also introduces new complexities:
- “rainbow spaghetti models” are a real challenge in OCPM and while actively researched we currently do not have the right user interface mechanisms and visualization concepts in place to tame it (at least in a way how we have learned to handle classical spaghetti models in practice: with sliders and filtering)
- OCPM can describe everything in the process as it is – but many users do not want to see everything, either because it is overwhelming, or because their interest, expertise, or responsibility lies in only a small part of the process. While OCPM here provides much more granular and natural opportunities to create relevant views on the data, e.g., by focusing on specific objects instead of a ll objects, both HCI and analysis approaches have to catch up with this paradigm in a way that reduces complexity for users instead of increasing it
All these technical challenges are prime research real estate and we can expect a lot of interesting research results in these (any many other) topics in the coming years. But solving them will not guarantee a smoother transition to OCPM.
Where does OCPM drive value?
Technologies and methods are adopted in society if they provide some form of benefit. In an industrial context, this benefit is often seen in specific, measurable value for the organization, for example through cost reduction, increased quality, increased productivity in the process itself or in the organization itself through improved well-being of workers or patients or reduced wear and tear of equipment. Value is highly context specific.
Process mining data models, algorithms, and dashboard do not generate value – regardless of whether they are case-centric or object-centric. Value is generated when the results of process mining can be used to realize a desired change in costs, quality, productivity, well-being, wear-and-tear, etc. Realizing value requires the organization (its people, machines, and systems) to perform the desired change.
That means object-centric process mining has to (better) interface with the organization to help it identify where change is needed and possible. We have figured out some answers to that question for the well-develop technology and methods stack of classical process mining. Specifically the area of simulation-driven process improvement where simulation models are learned from event data is mature with industrial platforms such as Apromore showing how to realize tangible insights for effective change.
But we hardly have a general answer that answers the question of how to effectively realize value (fast) with process mining – though it is gaining more research attention.
While I believe that OCPM has the potential to make the interfacing between process mining analysis and organizational (re)action more versatile – and as a consequence also easier to realize – OCPM will only succeed if research actually addresses the interfacing to the organization to realize value. A possible route has been described in the Manifesto for AI-Augmented BPM Systems.
There is certainly more…
Above, I touched on a lack of use-cases, techniques, and organizational embedding that hinder OCPM adoption in practice. I probably missed a lot of important aspects and details in each of them that have to be added – and will be added by the community over time.
Let me know what I have been missing.
But what I see as the one crucial hurdle is recognizing the interplay and dependencies between use case, techniques, and organizational embedding. Good use cases inspire good OCPM techniques, good OCPM techniques on relevant use cases will ease good organizational embedding. Expectations of good organizational embedding inspire good use cases. And it all requires good object-centric event data.
We will be faster in getting the full picture and make progress when practitioners, researchers, and vendors sit together at the same table. One way to make this happen is the ICPM Fellows Initiative which is organizing a first Online Session on OCPM to bring practitioners, researchers, and developers together.
I hope this overview inspires some of you to do so – reach out to researchers and pitch your case (pun intended).

One thought on “Why is transitioning to Object-Centric Process Mining non-trivial?”